神经网络基础
tags: real-examples math equations not-english table latex latex-environment
Description/Summary
Disclaimer This post is from the link posted by GitHub user Vonng in this comment. All credit for this post goes to the original author. Table of Contents 神经网络表示 神经元模型 单层神经网络模型 多层神经网络模型 神经网络推断 神经网络训练 代价函数 梯度下降算法 反向传播 反向传播误差δ 反向传播方程 反向传播方程的证明 神经网络的实现 神经网络优化 代价函数:交叉熵 规范化 神经网络相关基本知识笔记 神经网络表示 # 神经元模型 # 神经网络从大脑的工作原理得到启发,可用于解决通用的学习问题。神经网络的基本组成单元是 神经元(neuron) 。每个神经元具有一个轴突和多个树突。每个连接到本神经元的树突都是一个输入,当所有输入树突的兴奋水平之和超过某一阈值,神经元就会被激活。激活的神经元会沿着其轴突发射信号,轴突分出数以万计的树突连接至其他神经元,并将本神经元的输出并作为其他神经元的输入。数学上,神经元可以用 感知机 的模型表示。 一个神经元的数学模型主要包括以下内容: 名称 符号 说明 输入 (input) \(x\) 列向量 权值 (weight) \(w\) 行向量,维度等于输入个数 偏置 (bias) \(b\) 标量值,是阈值的相反数 带权输入 (weighted input) \(z\) \(z=w · x + b\) ,激活函数的输入值 激活函数 (activation function) \(σ\) 接受带权输入,给出激活值。 激活值 (activation) \(a\) 标量值,\(a = σ(\vec{w}·\vec{x}+b)\) 激活函数表达式 # \[ a = \sigma( \left[ \begin{matrix} w_{1} & ⋯ & w_{n} \\ \end{matrix}\right] · \left[ \begin{array}{x} x_1 \\ ⋮ \\ ⋮ \\ x_n \end{array}\right] + b ) \]
Content
- Disclaimer
- This post is from the link posted by GitHub user Vonng in this comment. All credit for this post goes to the original author.
神经网络相关基本知识笔记
神经网络表示 #
神经元模型 #
神经网络从大脑的工作原理得到启发,可用于解决通用的学习问题。神经网络的基本组成单元是 神经元(neuron) 。每个神经元具有一个轴突和多个树突。每个连接到本神经元的树突都是一个输入,当所有输入树突的兴奋水平之和超过某一阈值,神经元就会被激活。激活的神经元会沿着其轴突发射信号,轴突分出数以万计的树突连接至其他神经元,并将本神经元的输出并作为其他神经元的输入。数学上,神经元可以用 感知机 的模型表示。
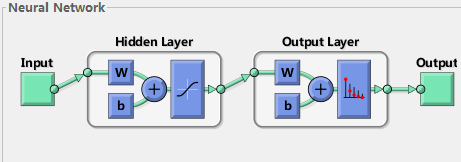
一个神经元的数学模型主要包括以下内容:
| 名称 | 符号 | 说明 |
|---|---|---|
| 输入 (input) | \(x\) | 列向量 |
| 权值 (weight) | \(w\) | 行向量,维度等于输入个数 |
| 偏置 (bias) | \(b\) | 标量值,是阈值的相反数 |
| 带权输入 (weighted input) | \(z\) | \(z=w · x + b\) ,激活函数的输入值 |
| 激活函数 (activation function) | \(σ\) | 接受带权输入,给出激活值。 |
| 激活值 (activation) | \(a\) | 标量值,\(a = σ(\vec{w}·\vec{x}+b)\) |
激活函数表达式 #
\[ a = \sigma( \left[ \begin{matrix} w_{1} & ⋯ & w_{n} \\ \end{matrix}\right] · \left[ \begin{array}{x} x_1 \\ ⋮ \\ ⋮ \\ x_n \end{array}\right] + b ) \]
激活函数通常使用S型函数,又称为sigmoid或者logsig,因为该函数具有良好的特性: 光滑可微 ,形状接近感知机所使用的硬极限传输函数,函数值与 导数值计算方便 。
\[ σ(z) = \frac 1 {1+e^{-z}} \]
\[ σ’(z) = σ(z)(1-σ(z)) \]
也有一些其他的激活函数,例如:硬极限传输函数(hardlim),对称硬极限函数(hardlims),线性函数(purelin), 对称饱和线性函数(satlins) ,对数-s形函数(logsig),正线性函数 (poslin),双曲正切S形函数(tansig),竞争函数(compet),有时候为了学习速度或者其他原因也会使用,表过不提。
单层神经网络模型 #
可以并行操作的神经元组成的集合,称为神经网络的一层。
现在考虑一个具有 \(n\) 个输入, \(s\) 个神经元(输出)的单层神经网络,则原来单个神经元的数学模型可扩展如下:
| 名称 | 符号 | 说明 |
|---|---|---|
| 输入 | \(x\) | 同层所有神经元共用输入,故输入保持不变,仍为 \((n×1)\) 列向量 |
| 权值 | \(W\) | 由 \(1 × n\) 行向量,变为 \(s × n\) 矩阵,每一行表示一个神经元的权值信息 |
| 偏$置 | \(b\) | 由 \(1 × 1\) 标量变为 \(s × 1\) 列向量 |
| 带权输入 | \(z\) | 由 \(1 × 1\) 标量变为 \(s × 1\) 列向量 |
| 激活值 | \(a\) | 由 \(1 × 1\) 标量变为 \(s × 1\) 列向量 |
激活函数向量表达式 #
\[ \left[ \begin{array}{a} a_1 \\ ⋮ \\ a_s \end{array}\right] = \sigma( \left[ \begin{matrix} w_{1,1} & ⋯ & w_{1,n} \\ ⋮ & ⋱ & ⋮ \\ w_{s,1} & ⋯ & w_{s,n} \\ \end{matrix}\right] · \left[ \begin{array}{x} x_1 \\ ⋮ \\ ⋮ \\ x_n \end{array}\right] + \left[ \begin{array}{b} b_1 \\ ⋮ \\ b_s \end{array}\right] ) \]
单层神经网络能力有限,通常都会将多个单层神经网络的输出和输入相连,组成多层神经网络。
多层神经网络模型 #
- 多层神经网络的层数从1开始计数,第一层为 输入层 ,第 \(L\) 层为 输出层 ,其它的层称为 隐含层 。
- 每一层神经网络都有自己的参数 \(W,b,z,a,⋯\) ,为了区别,使用上标区分: \(W^2,W^3,⋯\) 。
- 整个多层网络的输入,即为输入层的激活值 \(x=a^1\) ,整个网络的输出,即为输出层的激活值: \(y’=a^L\) 。
- 因为输入层没有神经元,所以该层所有参数中只有激活值 \(a^1\) 作为网络输入值而存在,没有 \(W^1,b^1,z^1\) 等。
现在考虑一个 \(L\) 层的神经网络,其各层神经元个数依次为: \(d_1,d_2,⋯,d_L\) 。则该网络的数学模型可扩展如下:
| 名称 | 符号 | 说明 |
|---|---|---|
| 输入 | \(x\) | 输入仍然保持不变,为 \((d_1×1)\) 列向量 |
| 权值 | \(W\) | 由 \(s × n\) 矩阵扩展为 \(L-1\) 个矩阵组成的列表: \(W^2_{d_2 × d_1},⋯,W^L_{d_L × d_{L-1}}\) |
| 偏置 | \(b\) | 由 \(s × 1\) 列向量扩展为 \(L-1\) 个列向量组成的列表: \(b^2_{d_2},⋯,b^L_{d_L}\) |
| 带权输入 | \(z\) | 由 \(s × 1\) 列向量扩展为 \(L-1\) 个列向量组成的列表: \(z^2_{d_2},⋯,z^L_{d_L}\) |
| 激活值 | \(a\) | 由 \(s × 1\) 列向量扩展为 \(L\) 个列向量 组成的列表: \(a^1_{d_1},a^2_{d_2},⋯,a^L_{d_L}\) |
激活函数矩阵表达式 #
\[ \left[ \begin{array}{a} a^l_1 \\ ⋮ \\ a^l_{d_l} \end{array}\right] = \sigma( \left[ \begin{matrix} w^l_{1,1} & ⋯ & w^l_{1,d_{l-1}} \\ ⋮ & ⋱ & ⋮ \\ w^l_{d_l,1} & ⋯ & w^l_{d_l,d_{l-1}} \\ \end{matrix}\right] · \left[ \begin{array}{x} a^{l-1}_1 \\ ⋮ \\ ⋮ \\ a^{l-1}_{d_{l-1}} \end{array}\right] + \left[ \begin{array}{b} b^l_1 \\ ⋮ \\ b^l_{d_l} \end{array}\right]) \]
权值矩阵的涵义 #
多层神经网络的权值由一系列权值矩阵表示
- 第 \(l\) 层网络的权值矩阵可记作 \(W^l\) ,表示前一层( \(l-1\) )到本层(\(l\))的连接权重
- \(W^l\) 的第 \(j\) 行可记作 \(W^l_{j*}\) ,表示从 \(l-1\) 层所有 \(d_{l-1}\) 个神经元出发,到达 \(l\) 层 \(j\) 号神经元的连接权重
- \(W^l\) 的第 \(k\) 列可记作 \(W^l_{*k}\) ,表示从 \(l-1\) 层第 \(k\) 号神经元出发,到达 \(l\) 层所有 \(d_l\) 个神经元的连接权重
- \(W^l\) 的 \(j\) 行 \(k\) 列可记作 \(W^l_{jk}\) ,表示从 \(l-1\) 层 \(k\) 号神经元出发,到达 \(l\) 层 \(j\) 神经元的连接权重
- 如图, \(w^3_{24}\) 表示从2层4号神经元到3层2号神经元的连接权值:
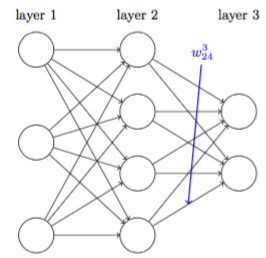
只要记住,权值矩阵 \(W\) 的 行标表示本层神经元 的标号, 列标表示上层神 经元 的标号即可。
神经网络推断 #
前馈(feed forward) 是指神经网络接受输入,产生输出的一次计算过程。又称为一次 推断(inference) 。
计算过程如下:
\begin{align} a^1 &= x \\ a^2 &= σ(W^2a^1 + b^2) \\ a^3 &= σ(W^3a^2 + b^3) \\ ⋯ \\ a^L &= σ(W^La^{L-1} + b^L) \\ y &= a^L \\ \end{align}
推断实际上就是一系列矩阵乘法与向量运算,一个训练好的神经网络可以高效地使用各种语言实现。神经网络的功能是通过推断而体现的。推断实现起来很简单,但如何 训练神经网络 才是真正的难点。
神经网络训练 #
神经网络的训练,是调整网络中的权值参数与偏置参数,从而提高网络工作效果的过程。
通常使用 梯度下降(Gradient Descent) 的方法来调整神经网络的参数,首先要定义一个 代价函数(cost function) 用以衡量神经网络的误差,然后通过梯度下降方法计算合适的参数修正量,从而 最小化 网络误差。
代价函数 #
代价函数是用于衡量神经网络工作效果的函数,是定义在一个或多个样本上的实值函数,通常应满足以下条件:
- 误差是非负的,神经网络效果越好,误差越小
- 代价可以写成神经网络输出的函数
- 总体代价等于个体样本代价的均值 : \(C=\frac{1}{n} \sum_x C_x\)
最常用的一个简单的代价函数是: 二次代价函数 ,又称为 均方误差 (MeanSquareError)
\[ C(w,b) = \frac{1}{2n} \sum_x{{\|y(x)-a\|}^2} \]
前面的系数 \(\frac 1 2\) 是为了求导后简洁的形式而添加的, \(n\) 是使用样本的数量,这里 \(y\) 和 \(x\) 都是已知的样本数据。
理论上任何可以反映网络工作效果的指标都可以作为代价函数。但之所以使用 MSE,而不是诸如"正确分类图像个数"的指标,是因为只有一个 光滑可导 的代价函数才可以使用 梯度下降 (Gradient Descent)调整参数。
样本的使用 #
代价函数的计算需要一个或多个训练样本。当训练样本非常多时,如果每轮训练都要重新计算网络整个训练集上所有样本的误差函数,开销非常大,速度难以接受。若只使用总体的一小部分,计算就能快很多。不过这样做依赖一个假设: 随机样本的代价,近似等于总体的代价。
按照使用样本的方式,梯度下降又分为:
-
批量梯度下降法(Batch GD):最原始的形式,更新每一参数都使用所有样本。可以得到全局最优解,易于并行实现,但当样本数量很多时,训练速度极慢。
-
随机梯度下降法(Stochastic GD):解决BGD训练慢的问题,每次随机使用一个样本。训练速度快,但准确度下降,且并不是全局最优,也不易于并行实现。
-
小批量梯度下降法(MiniBatch GD):在每次更新参数时使用b个样本(例如每次10个样本),在BGD与SGD中取得折中。
每次只使用一个样本时,又称为在线学习或递增学习。
当训练集的所有样本都被使用过一轮,称为完成一轮 迭代 。
梯度下降算法 #
若希望通过调整神经网络中的某个参数来减小整体代价,则可以考虑微分的方法。因为每层的激活函数,以及最终的代价函数都是光滑可导的。所以最终的代价函数 \(C\) 对于某个我们感兴趣的参数 \(w,b\) 也是光滑可导的。轻微拨动某个参数的值,最终的误差值也会发生连续的轻微的变化。不断地沿着参数的梯度方向,轻微调整每个参数的值,使得总误差值向下降的方向前进,最终达到极值点。就是梯度下降法的核心思想。
梯度下降的逻辑 #
现在假设代价函数 \(C\) 为两个变量 \(v_1,v_2\) 的可微函数,梯度下降实际上就是选择合适的 \(Δv\) ,使得 \(ΔC\) 为负。由微积分可知:
\[ ΔC ≈ \frac{∂C}{∂v_1} Δv_1 + \frac{∂C}{∂v_2} Δv_2 \]
这里 \(Δv\) 是向量: \(Δv = \left[ \begin{array}{v} Δv_1 \\ Δv_2 \end{array}\right]\) , \(∇C\) 是梯度向量 \(\left[ \begin{array}{C} \frac{∂C}{∂v_1} \\ \frac{∂C}{∂v_2} \end{array} \right]\) ,于是上式可重写为
\[ ΔC ≈ ∇C·Δv \]
怎样的 \(Δv\) 才能令代价函数的变化量为负呢?一种简单办法是令即 \(Δv\) 取一个与梯度 \(∇C\) 共线反向的小向量,此时 \(Δv = -η∇C\) ,则损失函数变化量 \(ΔC ≈ -η{∇C}^2\) ,可以确保为负值。按照这种方法,通过不断调整 \(v\) : \(v → v’ = v -η∇C\) ,使得 \(C\) 最终达到极小值点。
这即梯度下降的涵义所在: 所有参数都会沿着自己的梯度(导数)方向不断进行轻微下降, 使得总误差到达极值点。
对于神经网络,学习的参数实际上是权重 \(w\) 与偏置量 \(b\) 。原理是一样的,不过这里的 \(w,b\) 数目非常巨大
\[ w →w’ = w-η\frac{∂C}{∂w} \\ b → b’ = b-η\frac{∂C}{∂b} \]
真正棘手的问题在于梯度 \(∇C_w,∇C_b\) 的计算方式。如果使用微分的方法,通过 \(\frac {C(p+ε)-C} {ε}\) 来求参数的梯度,那么网络中的每一个参数都需要进行一次前馈和一次 \(C(p+ε)\) 的计算,在神经网络汪洋大海般的参数面前,这样的办法是行不通的。
反向传播(Back propagation)算法 可以解决这一问题。通过巧妙的简化,可以在一次前馈与一次反传中,高效地计算整个网络中所有参数梯度。
反向传播 #
反向传播算法接受一个打标样本 \((x,y)\) 作为输入,给出网络中所有参数 \((W,b)\) 的梯度。
反向传播误差δ #
反向传播算法需要引入一个新的概念:误差 \(δ\) 。误差的定义源于这样一种朴素的思想:如果轻微修改某个神经元的带权输入 \(z\) ,而最终代价 \(C\) 已不再变化,则可认为 \(z\) 已经到达极值点,调整的很好了。于是损失函数 \(C\) 对某神经元带权输入 \(z\) 的偏导 \(\frac {∂C}{∂z}\) 可以作为该神经元上误差 \(δ\) 的度量。故定义第 \(l\) 层的第 \(j^{th}\) 个神经元上的误差 \(δ^l_j\) 为:
\[ δ^l_j ≡ \frac{∂C}{∂z^l_j} \]
与激活值 \(a\) , 带权输入 \(z\) 一 样,误差也可以写作向量。第 \(l\) 层 的误差向量记作 \(δ^l\) 。 虽然看上去差不多,但之所以使用带权输入 \(z\) 而 不是激活值输出 \(a\) 来 定义本层的误差,有着形式上巧妙的设计。
引入反向传播误差的概念,是为了通过误差向量来计算梯度 \(∇C_w,∇C_b\) 。
反向传播算法一言蔽之:计算出 输出层误差 ,通过递推方程逐层回算出 每一层的误差 ,再由每一层的误差算出 本层的权值梯度与偏置梯度 。
这需要解决四个问题:
- 递推首项:如何计算输出层的误差: \(δ^L\)
- 递推方程:如何根据后一层的误差 \(δ^{l+1}\) 计 算前一层误差 \(δ^l\)
- 权值梯度:如何根据本层误差 \(δ^l\) 计 算本层权值梯度 \(∇W^l\)
- 偏置梯度:如何根据本层误差 \(δ^l\) 计 算本层偏置梯度 \(∇b^l\)
这四个问题,可以通过四个反向传播方程得到解决。
反向传播方程 #
| 方程 | 说明 | 编号 |
|---|---|---|
| \(δ^L = ∇C_a ⊙ σ’(z^L)\) | 输出层误差计算公式 | BP1 |
| \(δ^l = (W^{l+1})^T δ^{l+1} ⊙ σ’(z^l)\) | 误差传递公式 | BP2 |
| \(∇C_{W^l} = δ^l × {(a^{{l-1})}}T\) | 权值梯度计算公式 | BP3 |
| \(∇C_b = δ^l\) | 偏置梯度计算公式 | BP4 |
当误差函数取MSE: \(C = \frac 1 2 \|\vec{y} -\vec{a}\|^2= \frac 1 2 [(y_1 - a_1)^2 + \cdots + (y_{d_L} - a_{d_L})^2]\) ,激活函数取sigmoid时:
| 计算方程 | 说明 | 编号 |
|---|---|---|
| \(δ^L = (a^L - y) ⊙(1-a^L)⊙ a^L\) | 输出层误差需要 \(a^L\) 和 \(y\) | BP1 |
| \(δ^l = (W^{{l+1})}T δ^{l+1} ⊙(1-a^l)⊙ a^l\) | 本层误差需要:后层权值 \(W^{l+1}\) , 后层误差 \(δ^{l+1}\) , 本层输出\(a^l\) | BP2 |
| \(∇C_{W^l} = δ^l × {(a^{{l-1})}}T\) | 权值梯度需要:本层误差 \(δ^l\) , 前层输出\(a^{l-1}\) | BP3 |
| \(∇C_b = δ^l\) | 偏置梯度需要:本层误差\(δ^l\) | BP4 |
反向传播方程的证明 #
BP1:输出层误差方程 #
输出层误差方程给出了根据网络输出 \(a^L\) 与 标记结果 \(y\) 计 算输出层误差 \(δ\) 的 方法:
\[ δ^L = (a^L - y) ⊙(1-a^L)⊙ a^L \]
证明 #
因为 \(a^L = σ(z^L)\) ,本方程可以直接从反向传播误差的定义,通过 \(a^L\) 作为中间变量链 式求导 推导得出:
\[ \frac{∂C}{∂z^L} = \frac{∂C}{∂a^L} \frac{∂a^L}{∂z^L} = ∇C_a σ’(z^L) \]
而因为误差函数 \(C = \frac 1 2 \|\vec{y} -\vec{a}\|^2= \frac 1 2 [(y_1 - a_1)^2 + ⋯ + (y_{d_L} - a_{d_L})^2]\) ,方程两侧对某个 \(a_j\) 取偏导则有:
\[ \frac {∂C}{∂a^L_j} = (a^L_j-y_j) \]
因为误差函数中,其他神经元的输出不会影响到误差函数对神经元 \(j\) 输出的偏导,系数也正好平掉了。写作向量形式即为: \((a^L - y)\) 。另一方面,易证 \(σ’(z^L) = (1-a^L)⊙ a^L\) 。
QED
BP2:误差传递方程 #
误差传递方程给出了根据后一层误差计算前一层误差的方法:
\[ δ^l = (W^{l+1})^T δ^{l+1} ⊙ σ’(z^l) \]
证明 #
本方程可以直接从反向传播误差的定义,以后一层所有神经元的带权输入 \(z^{l+1}\) 作 为中间变量进行链式求导推导出:
\[ δ^l_j = \frac {∂C}{∂z^l_j} = \sum_{k=1}^{d_{l+1}} \frac{∂C}{∂z^{l+1}_k} \frac{∂z^{l+1}_k}{∂z^{l}_j} = \sum_{k=1}^{d_{l+1}} (δ^{l+1}_k \frac{∂z^{l+1}_k}{∂z^{l}_j}) \]
通过链式求导,引入后一层带权输入作为中间变量,从而在方程右侧引入后一层误差的表达形式。现在要解决的就是 \(\frac{∂z^{l+1}_k}{∂z^{l}_j}\) 是 什么的问题。由带权输入的定义 \(z = wx + b\) 可知:
\[ z^{l+1}_k = W^{l+1}_{k,*} ·a^l + b^{l+1}_{k} = W^{l+1}_{k,*} · σ(z^{l}) + b^{l+1}_{k} = \sum_{j=1}^{d_{l}}(w_{kj}^{l+1} σ(z^{l_j})) + b^{l+1}_{k} \]
两边同时对 \(z^{l}_j\) 求 导可以得到:
\[ \frac{∂z^{l+1}_k}{∂z^{l}_j} = w^{l+1}_{kj} σ’(z^l) \]
回代则有:
\begin{align} δ^l_j & = \sum_{k=1}^{d_{l+1}} (δ^{l+1}_k \frac{∂z^{l+1}_k}{∂z^{l}_j}) \\ & = σ’(z^l) \sum_{k=1}^{d_{l+1}} (δ^{l+1}_k w^{l+1}_{kj}) \\ & = σ’(z^l) ⊙ [(δ^{l+1}) · W^{l+1}_{*.j}] \\ & = σ’(z^l) ⊙ [(W^{l+1})^T_{j,*} · (δ^{l+1}) ]\\ \end{align}
这里,对后一层所有神经元的误差权值之积求和,可以改写为两个向量的点积:
- 后一层 \(k\) 个 神经元的误差向量
- 后一层权值矩阵的第 \(j\) 列 ,即所有从本层 \(j\) 神 经元出发前往下一层所有 \(k\) 个 神经元的权值。
又因为向量点积可以改写为矩阵乘法:以行向量乘以列向量的方式进行,所以将权值矩阵转置,原来拿的是列,现在则拿出了行向量。这时候再改写回向量形式为:
\[ δ^l = σ’(z^l) ⊙ (W^{l+1})^Tδ^{l+1} \]
QED
BP3:权值梯度方程 #
每一层的权值梯度 \(∇C_{W^l}\) 可 以根据本层的误差向量(列向量),与上层的输出向量(行向量)的外积得出。
\[ ∇C_{W^l} = δ^l × {(a^{l-1})}^T \]
证明 #
由误差的定义,以 \(w^l_{jk}\) 作 为中间变量求偏导可得:
\begin{align} δ^l_j & = \frac{∂C}{∂z^l_j} = \frac{∂C}{∂w^l_{jk}} \frac{∂ w_{jk}}{∂ z^l_j} = ∇C_{w^l_{jk}} \frac{∂w_{jk}}{∂ z^l_j} \end{align}
由定义可得,第 \(l\) 层 第 \(j\) 个 神经元的带权输入 \(z^l_j\) :
\[ z^l_j = \sum_k w^l_{jk} a^{l-1}_k + b^l_j \]
两侧对 \(w_{jk}^l\) 求 导得到:
\[ \frac{\partial z_j}{\partial w^l_{jk}} = a^{l-1}_k \]
代回则有: \[ ∇C_{w^l_{jk}} = δ^l_j \frac{∂ z^l_j}{∂w_{jk}} = δ^l_j a^{l-1}_k \] 观察可知,向量形式是一个外积: \[ ∇C_{W^l} = δ^l × {(a^{l-1})}^T \]
-
本层误差行向量 : \(δ^l\) ,维度为(\(d_l \times 1\))
-
上层激活列向量 : \((a^{l-1})^T\) ,维度为(\(1 \times d_{l-1}\))
QED
BP4:偏置梯度方程 #
\[ ∇C_b = δ^l \]
证明 #
由定义可知:
\[ δ^l_j = \frac{∂C}{∂z^l_j} = \frac{∂C}{∂b^l_j} \frac{∂b_j}{∂z^l_j} = ∇C_{b^l_{j}} \frac{∂b_j}{∂z^l_j} \]
因为 \(z^l_j = W^l_{*,j} \cdot a^{l-1} + b^l_j\) ,两侧对 \(z_j^l\) 求 导得到 \(1=\frac{∂b_j}{∂z^l_j}\) 。 于是回代得到: \(∇C_{b^l_{j}} =δ^l_j\) ,
QED
至此,四个方程均已证毕。只要将其转换为代码即可工作。
神经网络的实现 #
作为概念验证,这里给出了MNIST手写数字分类神经网络的Python实现。
# coding: utf-8
# author: vonng(fengruohang@outlook.com)
# ctime: 2017-05-10
import random
import numpy as np
class Network(object):
def __init__(self, sizes):
self.sizes = sizes
self.L = len(sizes)
self.layers = range(0, self.L - 1)
self.w = [np.random.randn(y, x) for x, y in zip(sizes[:-1], sizes[1:])]
self.b = [np.random.randn(x, 1) for x in sizes[1:]]
def feed_forward(self, a):
for l in self.layers:
a = 1.0 / (1.0 + np.exp(-np.dot(self.w[l], a) - self.b[l]))
return a
def gradient_descent(self, train, test, epoches=30, m=10, eta=3.0):
for round in range(epoches):
# generate mini batch
random.shuffle(train)
for batch in [train_data[k:k + m] for k in xrange(0, len(train), m)]:
x = np.array([item[0].reshape(784) for item in batch]).transpose()
y = np.array([item[1].reshape(10) for item in batch]).transpose()
n, r, a = len(batch), eta / len(batch), [x]
# forward & save activations
for l in self.layers:
a.append(1.0 / (np.exp(-np.dot(self.w[l], a[-1]) - self.b[l]) + 1))
# back propagation
d = (a[-1] - y) * a[-1] * (1 - a[-1]) #BP1
for l in range(1, self.L): # l is reverse index since last layer
if l > 1: #BP2
d = np.dot(self.w[-l + 1].transpose(), d) * a[-l] * (1 - a[-l])
self.w[-l] -= r * np.dot(d, a[-l - 1].transpose()) #BP3
self.b[-l] -= r * np.sum(d, axis=1, keepdims=True) #BP4
# evaluate
acc_cnt = sum([np.argmax(self.feed_forward(x)) == y for x, y in test])
print "Round {%d}: {%s}/{%d}" % (round, acc_cnt, len(test_data))
if __name__ == '__main__':
import mnist_loader
train_data, valid_data, test_data = mnist_loader.load_data_wrapper()
net = Network([784, 100, 10])
net.gradient_descent(train_data, test_data, epoches=100, m=10, eta=2.0)
数据加载脚本: mnist_loader.py
。输入数据为二元组列表: (input(784,1), output(10,1))
$ python net.py
Round {0}: {9136}/{10000}
Round {1}: {9265}/{10000}
Round {2}: {9327}/{10000}
Round {3}: {9387}/{10000}
Round {4}: {9418}/{10000}
Round {5}: {9470}/{10000}
Round {6}: {9469}/{10000}
Round {7}: {9484}/{10000}
Round {8}: {9509}/{10000}
Round {9}: {9539}/{10000}
Round {10}: {9526}/{10000}
一轮迭代后,网络在测试集上的分类准确率就达到90%,最终收敛至96%左右。
对于五十行代码,这个效果是值得惊叹的。然而96%的准确率在实际生产中恐怕仍然是无法接受的。想要达到更好的效果,就需要对神经网络进行优化。
神经网络优化 #
神经网络的基础知识也就这么多,但优化其表现却是一个无尽的挑战。每一种优化的手段都可以当做一个进阶的课题深入研究。优化手段也是八仙过海各显神通:有数学,有科学,有工程学,也有哲学,还有玄学…
改进神经网络的学习效果有几种主要的方法:
- 选取 更好的代价函数 :例如 交叉熵(cross-entropy)
- 规范化(regularization) : L2规范化 、弃权、L1规范化
- 采用其他的 激活神经元 :线性修正神经元(ReLU),双曲正切神经元(tansig)
- 修改神经网络的输出层: 柔性最大值(softmax)
- 修改神经网络输入的组织方式:递归神经网络(Recurrent NN),卷积神经网络(Convolutional NN)。
- 添加层数:深度神经网络(Deep NN)
- 通过尝试,选择合适的 超参数(hyper-parameters) ,按照迭代轮数或评估效果动态调整超参数。
- 采用其他的梯度下降方法:基于动量的梯度下降
- 使用更好的 初始化权重
- 人为扩展已有训练数据集
这里介绍两种方法, 交叉熵代价函数 与 L2规范化 。因为它们:
- 实现简单,修改一行代码即可实现,还减小了计算开销。
- 效果立竿见影,将分类错误率从4%降低到2%以下。
代价函数:交叉熵 #
MSE是一个不错的代价函数,然而它存在一个很尴尬的问题:学习速度。
MSE输出层误差的计算公式为: \[ δ^L = (a^L - y)σ’(z^L) \]
sigmoid又称为逻辑斯蒂曲线,其导数 \(σ’\) 是 一个钟形曲线。所以当带权输入 \(z\) 从 大到小或从小到大时,梯度的变化会经历一个"小,大,小"的过程。学习的速度也会被导数项拖累,存在一个"慢,快,慢"的过程。
| MSE | Cross Entropy |
|---|---|
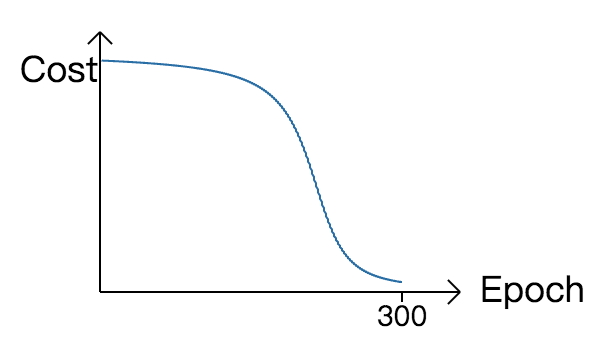 |
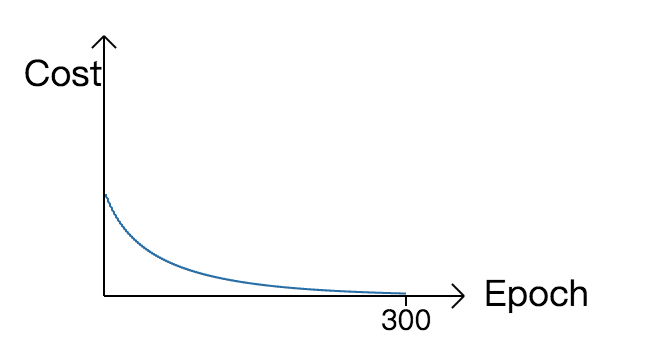 |
若采用 交叉熵(cross entropy) 误差函数:
\[ C = - \frac 1 n \sum_x [ y ln(a) + (1-y)ln(1-a)] \]
对于单个样本,即
\[ C = - [ y ln(a) + (1-y)ln(1-a)] \]
虽然看起来很复杂,但输出层的误差公式变得异常简单,变为: \(δ^L = a^L - y\)
比起MSE少掉了导数因子,所以误差直接和(预测值-实际值)成正比,不会遇到学习速度被激活函数的导数拖慢的问题,计算起来也更为简单。
证明 #
\(C\) 对 网络输出值 \(a\) 求 导,则有:
\[ ∇C_a = \frac {∂C} {∂a^L} = - [ \frac y a - \frac {(1-y)} {1-a}] = \frac {a - y} {a (1-a)} \]
反向传播的四个基本方程里,与误差函数 \(C\) 相 关的只有BP1:即输出层误差的计算方式。
\[ δ^L = ∇C_a ⊙ σ’(z^L) \]
现在 \(C\) 换 了计算方式,将新的误差函数 \(C\) 对 输出值 \(a^L\) 的 梯度 \(\frac {∂C} {∂a^L}\) 带回BP1,即有:
\[ δ^L = \frac {a - y} {a (1-a)}× a(1-a) = a-y \]
规范化 #
拥有大量的自由参数的模型能够描述特别神奇的现象。
费米说:“With four parameters I can fit an elephant, and with five I can make him wiggle his trunk”。神经网络这种动辄百万的参数的模型能拟合出什么奇妙的东西是难以想象的。
一个模型能够很好的拟合已有的数据,可能只是因为模型中足够的自由度,使得它可以描述几乎所有给定大小的数据集,而不是真正洞察数据集背后的本质。发生这种情形时, 模型对已有的数据表现的很好,但是对新的数据很难泛化 。这种情况称为 过拟合(overfitting) 。
例如用3阶多项式拟合一个带随机噪声的正弦函数,看上去就还不错;而10阶多项式,虽然完美拟合了数据集中的所有点,但实际预测能力就很离谱了。它拟合的更多地是数据集中的噪声,而非数据集背后的潜在规律。
x, xs = np.linspace(0, 2 * np.pi, 10), np.arange(0, 2 * np.pi, 0.001)
y = np.sin(x) + np.random.randn(10) * 0.4
p1,p2 = np.polyfit(x, y, 10), np.polyfit(x, y, 3)
plt.plot(xs, np.polyval(p1, xs));plt.plot(x, y, 'ro');plt.plot(xs, np.sin(xs), 'r--')
plt.plot(xs, np.polyval(p2, xs));plt.plot(x, y, 'ro');plt.plot(xs, np.sin(xs), 'r--')
| 3阶多项式 | 10阶多项式 |
|---|---|
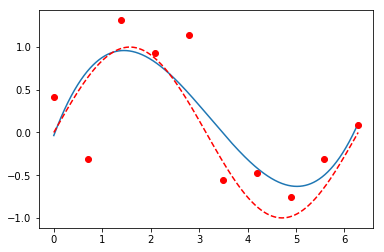 |
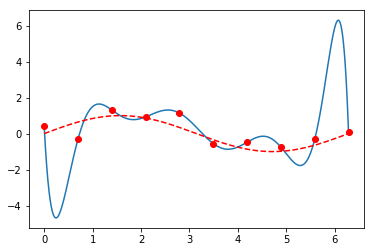 |
一个模型真正的测验标准,是它对没有见过的场景的预测能力,称为 泛化能力(generalize) 。
如何避免过拟合?按照奥卡姆剃刀原理: 两个效果相同的解释,选择简单的那一个。
当然这个原理只是我们抱有的一种信念,并不是真正的定理铁律:这些数据点真的由拟合出的十阶多项式产生,也不能否认这种可能…
总之,如果出现非常大的权重参数,通常就意味着过拟合。例如拟合所得十阶多项式系数就非常畸形:
-0.001278386964370502
0.02826407452052734
-0.20310716176300195
0.049178327509096835
7.376259706365357
-46.295365250182925
135.58265224859255
-211.767050023543
167.26204130954324
-50.95259728945658
0.4211227089756039
通过添加权重衰减项,可以有效遏制过拟合。例如 \(L2\) 规 范化为损失函数添加了一个 \(\frac λ 2 w^2\) 的惩罚项:
\[ C = -\frac{1}{n} \sum_{xj} \left[ y_j \ln a^L_j+(1-y_j) \ln (1-a^L_j)\right] + \frac{\lambda}{2n} \sum_w w^2 \]
所以,权重越大,损失值越大,这就避免神经网络了向拟合出畸形参数的方向发展。
这里使用的是交叉熵损失函数。但无论哪种损失函数,都可以写成:
\[ C = C_0 + \frac {λ}{2n} \sum_w {w^2} \]
其中原始的代价函数为 \(C_0\) 。 那么,原来损失函数对权值的偏导,就可以写成:
\[ \frac{∂C}{∂w} = \frac{ ∂C_0}{∂w}+\frac{λ}{n} w \]
因此,引入 \(L2\) 规 范化惩罚项在计算上的唯一变化,就是在处理权值梯度时首先要乘一个衰减系数:
\[ w → w’ = w\left(1 - \frac{ηλ}{n} \right) - η\frac{∂C_0}{∂ w} \]
注意这里的 \(n\) 是 所有的训练样本数,而不是一个小批次使用的训练样本数。
改进实现 #
# coding: utf-8
# author: vonng(fengruohang@outlook.com)
# ctime: 2017-05-10
import random
import numpy as np
class Network(object):
def __init__(self, sizes):
self.sizes = sizes
self.L = len(sizes)
self.layers = range(0, self.L - 1)
self.w = [np.random.randn(y, x) / np.sqrt(x) for x, y in zip(sizes[:-1], sizes[1:])]
self.b = [np.random.randn(x, 1) for x in sizes[1:]]
def feed_forward(self, a):
for l in self.layers:
a = 1.0 / (1.0 + np.exp(-np.dot(self.w[l], a) - self.b[l]))
return a
def gradient_descent(self, train, test, epoches=30, m=10, eta=0.1, lmd=5.0):
n = len(train)
for round in range(epoches):
random.shuffle(train)
for batch in [train_data[k:k + m] for k in xrange(0, len(train), m)]:
x = np.array([item[0].reshape(784) for item in batch]).transpose()
y = np.array([item[1].reshape(10) for item in batch]).transpose()
r = eta / len(batch)
w = 1 - eta * lmd / n
a = [x]
for l in self.layers:
a.append(1.0 / (np.exp(-np.dot(self.w[l], a[-1]) - self.b[l]) + 1))
d = (a[-1] - y) # cross-entropy BP1
for l in range(1, self.L):
if l > 1: # BP2
d = np.dot(self.w[-l + 1].transpose(), d) * a[-l] * (1 - a[-l])
self.w[-l] *= w # weight decay
self.w[-l] -= r * np.dot(d, a[-l - 1].transpose()) # BP3
self.b[-l] -= r * np.sum(d, axis=1, keepdims=True) # BP4
acc_cnt = sum([np.argmax(self.feed_forward(x)) == y for x, y in test])
print "Round {%d}: {%s}/{%d}" % (round, acc_cnt, len(test_data))
if __name__ == '__main__':
import mnist_loader
train_data, valid_data, test_data = mnist_loader.load_data_wrapper()
net = Network([784, 100, 10])
net.gradient_descent(train_data, test_data, epoches=50, m=10, eta=0.1, lmd=5.0)
Round {0}: {9348}/{10000}
Round {1}: {9538}/{10000}
Round {2}: {9589}/{10000}
Round {3}: {9667}/{10000}
Round {4}: {9651}/{10000}
Round {5}: {9676}/{10000}
...
Round {25}: {9801}/{10000}
Round {26}: {9799}/{10000}
Round {27}: {9806}/{10000}
Round {28}: {9804}/{10000}
Round {29}: {9804}/{10000}
Round {30}: {9802}/{10000}
可见只是简单的变更,就使准确率有了显著提高,最终收敛至98%。
修改Size为 [784,128,64,10] 添加一层隐藏层,可以进一步提升测试集准确率至98.33%,验证集至98.24%。
对于MNIST数字分类任务,目前最好的准确率为99.79%,那些识别错误的case,恐怕人类想要正确识别也很困难。神经网络的分类效果最新进展可以参看这里: classification_datasets_results。
本文是tensorflow官方推荐教程:Neural Networks and Deep Learning的笔记整理,原文 Github Page。
Page (Debug)
| Page Variable | Value | |
|---|---|---|
| Name | "神经网络基础" | |
| Title | "神经网络基础" | |
| ResourceType | "page" | |
| Kind | "page" | |
| Section | "real-examples" | |
| Draft | false | |
| Type | "real-examples" | |
| Layout | "" | |
| Permalink | "https://ox-hugo.scripter.co/test/real-examples/nn-intro/" | |
| RelPermalink | "/real-examples/nn-intro/" | |
| Data |
| |
| NextPage | Default Creator | |
| PrevPage | Multifractals in ecology using R | |
| NextInSection | None | |
| PrevInSection | Multifractals in ecology using R |
Page Params (Debug)
| Key | Type | Value |
|---|---|---|
| author | []string | "Feng Ruohang" |
| date | time.Time | 2017-11-29 00:00:00 +0000 UTC |
| draft | bool | false |
| iscjklanguage | bool | false |
| lastmod | time.Time | 2022-01-12 00:29:48 -0500 -0500 |
| publishdate | time.Time | 2017-11-29 00:00:00 +0000 UTC |
| source | string | "https://github.com/Vonng/Math/blob/master/nndl/nn-intro.md" |
| tags | []string | "real-examples" "math" "equations" "not-english" "table" "latex" "latex-environment" |
| title | string | "神经网络基础" |
File Object (Debug)
| FileInfo Variable | Value |
|---|---|
| UniqueID | "c8d3900fa96e7847f7c8facaa3b85fe6" |
| BaseFileName | "nn-intro" |
| TranslationBaseName | "nn-intro" |
| Lang | "en" |
| Section | "real-examples" |
| LogicalName | "nn-intro.md" |
| Dir | "real-examples/" |
| Ext | "md" |
| Path | "real-examples/nn-intro.md" |